Ocean Rendering, Part 2 - Profiling and Optimization
Continuing the ocean rendering journey by improving performance.
Navigation: [Part 1] [Part 2]
Chapters
- Introduction
- Baseline
- Optimization 1: FP16 Textures
- Optimization 2: Coarse Culling
- Optimization 3: Index Buffer
- Optimization 4: Z-Curve Index Buffer
- Optimization 5: Texture Repacking and Quantization
- Optimization 6: Level of Detail
- Summary
Introduction
Before optimizing it is important to construct a benchmark for consistency and create a baseline to optimize against. The camera is in a fixed position and time is stopped. All captures were taken at a resolution of 1440p with clocks locked to boost on an RTX 4070.
Baseline
The ocean simulation is set to use four cascades (simulation domains), with each cascade generating two 256x256 R32G32B32A32 textures, representing the 3D displacement and the five partial derivatives required for shading.
The rendering is split into a depth pre-pass and the shading pass, the latter being referred as an opaque pass in the captures.
The depth pre-pass was implemented in preparation to implementing translucency, in hindsight, however, it also was an optimization.
A single tile with 2048x2048 vertices is drawn with a distance of 0.25 between every vertex, and there is neither a vertex buffer nor an index buffer – the tile is generated in the vertex shader based on the drawcall information.
Each vertex requires up to four texture samples for the displacement, and each fragment in the pixel shader needs to sample both displacement and partial derivative textures due to how the values are packed.
I have also implemented a very simple distance-based weight calculated for each cascade, with a weight of 0.0 disabling the texture sample of the cascade.
Now that the current implementation is explained, here’s the baseline capture:
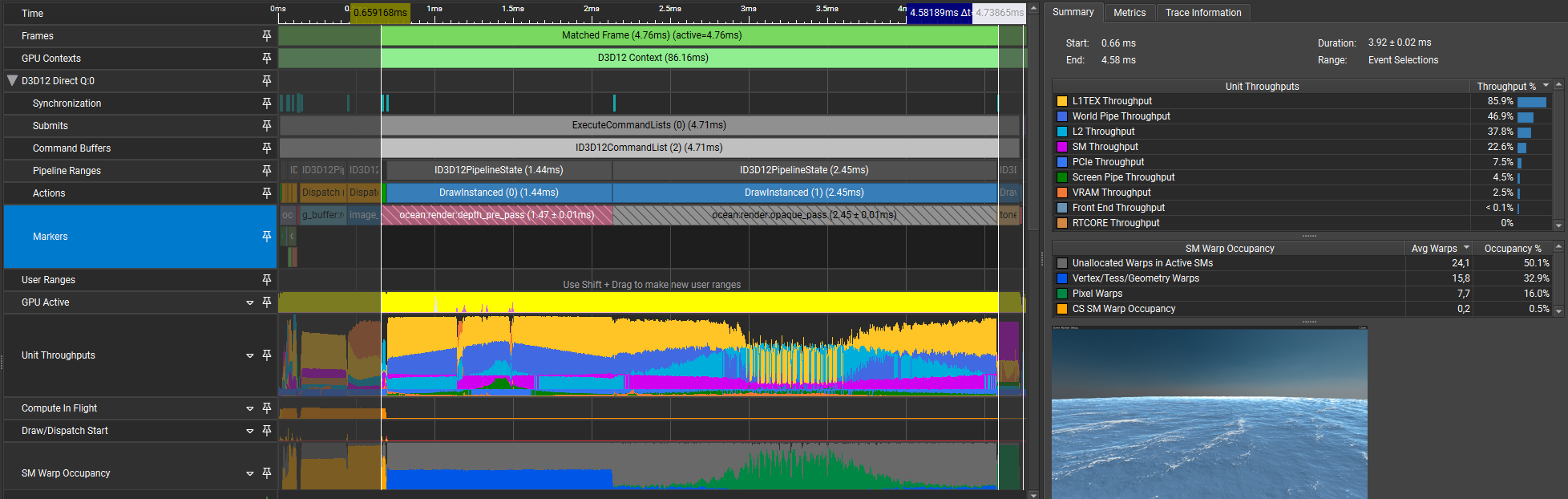
| Pass | Time (pass) | Time (cumulative) |
|---|---|---|
| Simulation | 0.11ms | 0.11ms |
| Depth pre-pass | 1.47ms | 1.58ms |
| Opaque pass | 2.45ms | 4.03ms |
The first things we can see when inspecting the capture is that L1TEX throughput is through the roof as well as occupancy being extremely low for both shading passes. This being said, we’re L1TEX bound and thus removing pressure there should help us gain significant speed increases.
Optimization 1: FP16 Textures
Starting out with a simple optimization.
Changing the texture formats from the simulation to R16G16B16A16 should help a lot without causing a loss in quality.
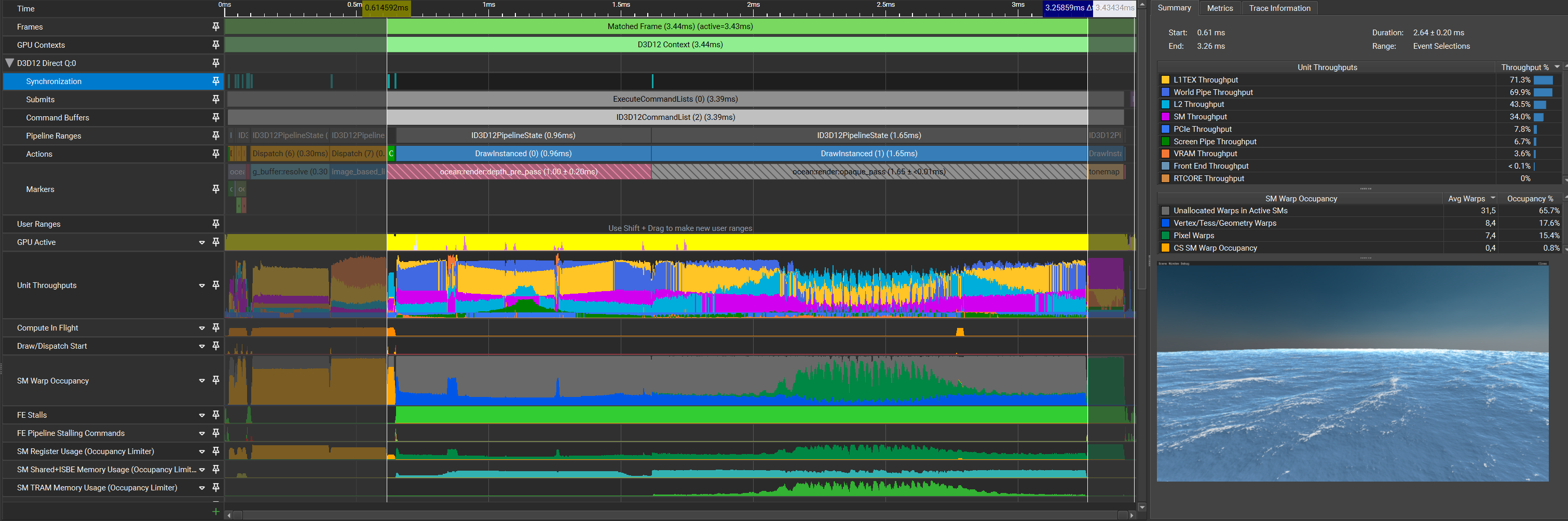
| Pass | Time (pass) | Time (cumulative) |
|---|---|---|
| Simulation | 0.08ms | 0.08ms |
| Depth pre-pass | 1.00ms | 1.08ms |
| Opaque pass | 1.65ms | 2.73ms |
To absolutely no one’s surprise, reducing the texture size and thus reducing the bandwidth makes quite a significant impact in frame time, reducing it by 1.27ms across the depth pre pass and shading pass combined! What’s interesting now is that there are sections in which the limiting factor is World Pipe throughput. Given that neither vertex nor index buffers are used, the Primitive Distributor (PD) and Vertex Attribute Fetch (VAF) units aren’t the culprits. This leaves the PES+VPC unit. Because there aren’t any tesselation or geometry shaders to be found anywhere in this renderer, the only candidate left is VPC, which is responsible for clip and cull.
Optimization 2: Coarse Culling
Every vertex needs to sample the displacement for every cascade, thus reducing the amount of geometry processing should alleviate some L1TEX pressure and potentially some VPC pressure. The obvious first step to reduce overhead incurred by geometry processing is to reduce the amount of geometry that is processed in the first place. Starting simple, The ocean surface is split into a 16x16 grid of tiles with 128x128 vertices each. Each tile will go through CPU-based frustum culling, with an arbitrary grace factor to account for displacement beyond the tile-boundaries.
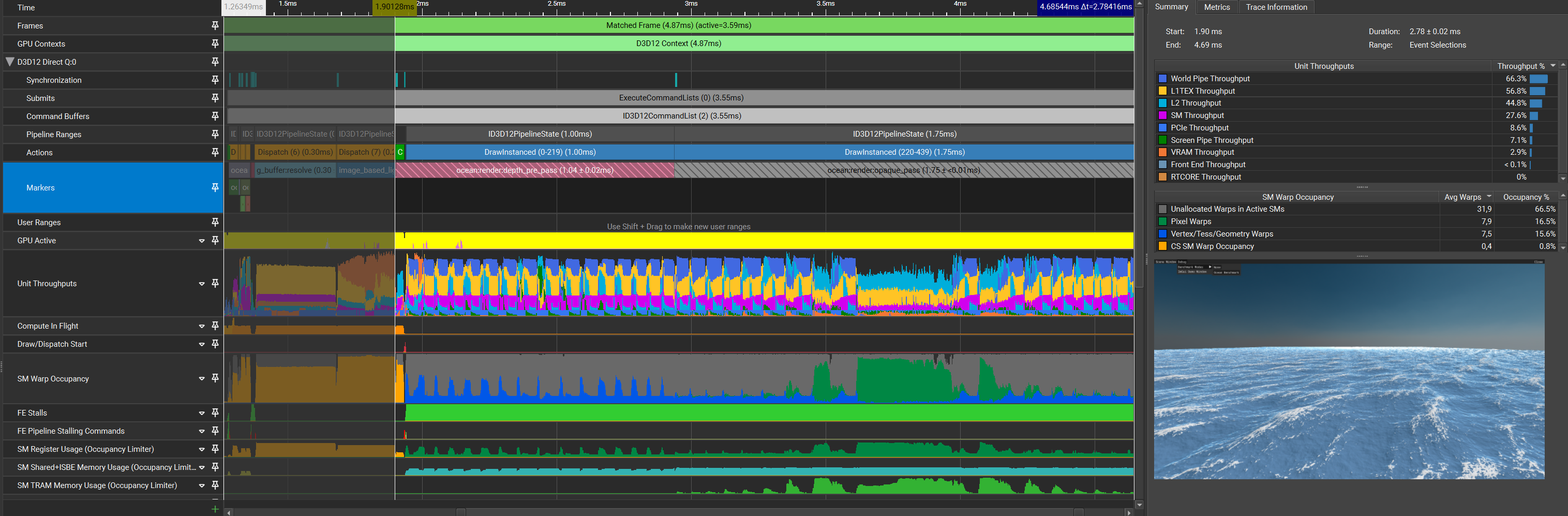
| Pass | Time (pass) | Time (cumulative) |
|---|---|---|
| Simulation | 0.09ms | 0.09ms |
| Depth pre-pass | 1.04ms | 1.13ms |
| Opaque pass | 1.75ms | 2.88ms |
Surprisingly, instead of improving performance, it got slower. An interesting wave-like shape now appears in both the depth pre pass and the shading pass. The World Pipe bottleneck also seems to be more apparent than before, with L1TEX being reduced drastically in both passes.
Optimization 3: Index Buffer
Without an index buffer the GPU cannot assume that any vertex is reused, so for every vertex, every triangle that touches it samples the textures again despite the data not changing. Given the structure of the grid, every vertex position has its displacement sampled up to 6 times. Using an index buffer should allow the GPU to re-use most of the vertices so long as the vertex cache isn’t full, leading to a large reduction in texture samples in the vertex shader. A vertex buffer is not required to allow for this re-use. My implementation here simply goes from quad to quad across all rows and columns in the grid, giving us the following capture:
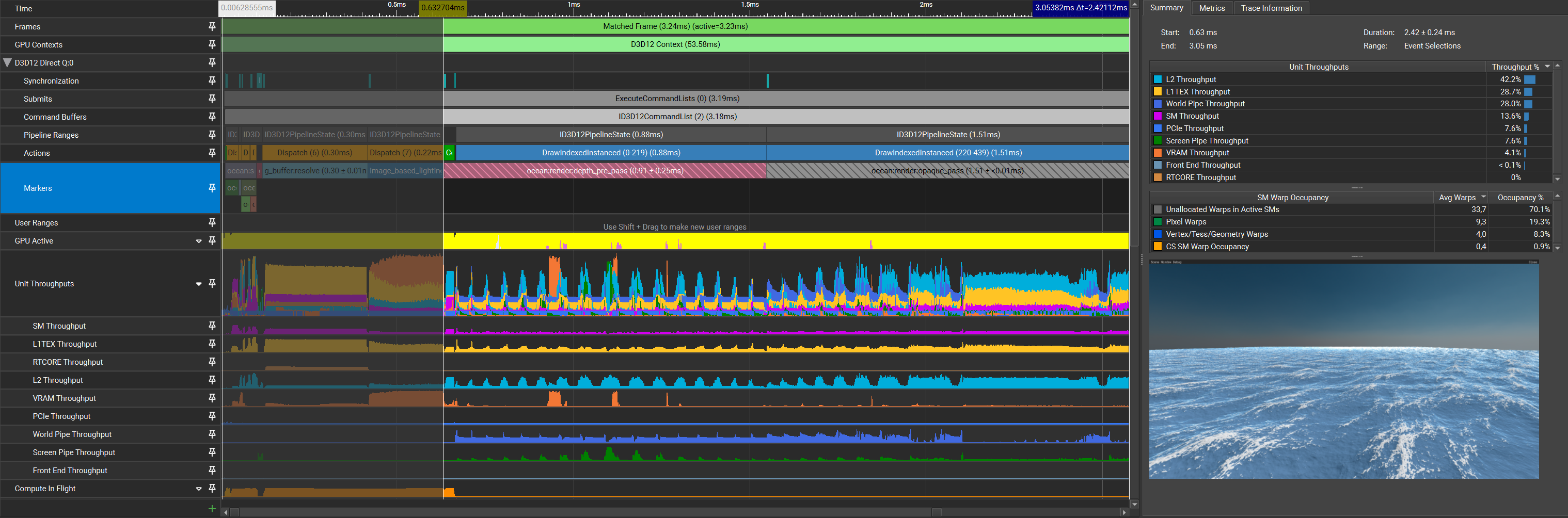
| Pass | Time (pass) | Time (cumulative) |
|---|---|---|
| Simulation | 0.09ms | 0.09ms |
| Depth pre-pass | 0.91ms | 1.00ms |
| Opaque pass | 1.51ms | 2.51ms |
The reduction in throughput across most units as well as the improved timings prove that the index buffer helped.
Optimization 4: Z-Curve Index Buffer
Further reordering the indices to maximize locality and thus minimizing the amount of repeated texture samples will further improve the vertex cache utilization. One way of doing so is by ordering the vertices to be accessed in a Z-curve.
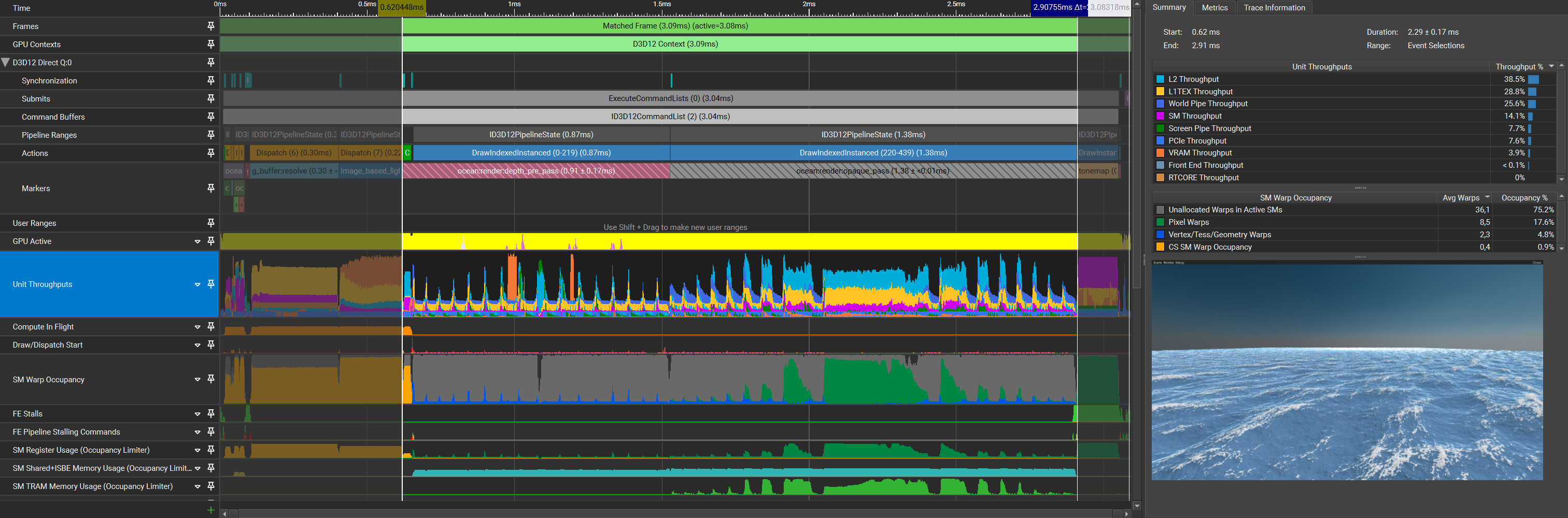
| Pass | Time (pass) | Time (cumulative) |
|---|---|---|
| Simulation | 0.08ms | 0.08ms |
| Depth pre-pass | 0.91ms | 0.99ms |
| Opaque pass | 1.38ms | 2.37ms |
As can be seen in the capture and the timings, World Pipe throughput has been reduced by a small amount and the timings improved a little.
Optimization 5: Texture Repacking and Quantization
Considering the huge amount of texture samples required and following the logic when going to fp16, further reducing the size of textures should still help improve performance.
There is now an additional dispatch that calculates the min/max values from the initial simulation output, which is used to quantize the results into a reordered set of textures: R8G8B8A8 displacement, R8 and R8G8B8A8 for the partial derivatives.
That extra dispatch takes roughly 1 microsecond, so I’ll omit it from the measurements.
The repacking removes the unnecessary displacement samples from the pixel shader.
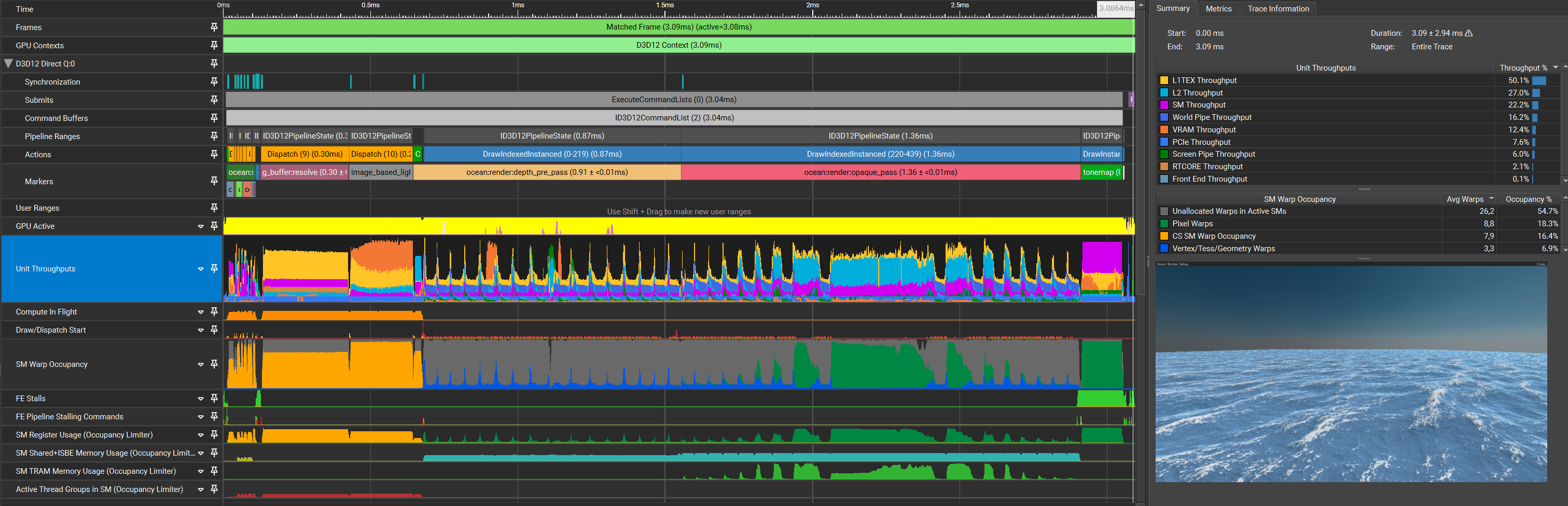
| Pass | Time (pass) | Time (cumulative) |
|---|---|---|
| Simulation | 0.09ms | 0.09ms |
| Repack + Quantize | 0.01ms | 0.10ms |
| Depth pre-pass | 0.91ms | 1.01ms |
| Opaque pass | 1.36ms | 2.37ms |
Seeing how reducing the size of the data that’s being sampled only resulted in changes within the margin of error and doesn’t change the captured output by that much, there’s still an elephant in the room that needs to be addressed that’ll provide another huge improvement – occupancy. That being said, it’s not surprising that no improvement appeared here. The occupancy is so low that even if this presumed optimization improved parts of the pipeline that they don’t show up at all.
Optimization 6: Level of Detail
Now to the elephant in the room, which I will name “LOD system”. Up until now, the ocean tiles all had the same size and thus also the same scale. Implementing a simple CPU-based LOD system will help in many ways: reducing quad-overdraw, reducing vertex shader texture samples, and further reducing VPC pressure – and in return, vastly improve occupancy. For future work I’ll likely implement Jonathan Dupuy’s Concurrent Binary Tree data structure, as it would be quite a perfect fit for the ocean.


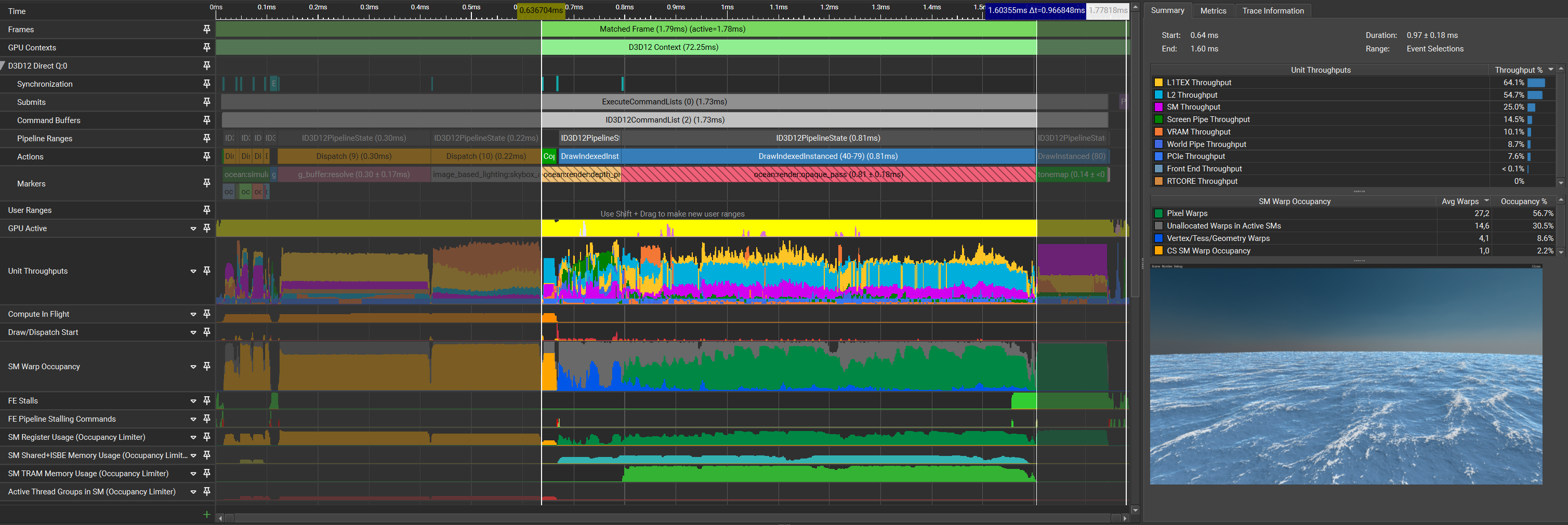
| Pass | Time (pass) | Time (cumulative) |
|---|---|---|
| Simulation | 0.08ms | 0.08ms |
| Repack + Quantize | 0.01ms | 0.09ms |
| Depth pre-pass | 0.16ms | 0.25ms |
| Opaque pass | 0.81ms | 1.06ms |
The capture no longer contains the wave-like structure that all captures prior showed. This also highly correlates with the improvement in occupancy, where in previous captures the unallocated warps in active SMs were extremely dominant.
Summary
With the LOD system implemented, I’m quite happy with the current results and excited to keep improving the ocean rendering. Most interesting to me during this optimization process was noticing how something that theoretically improves the algorithm can result in little to no change at all simply due to another issue dwarfing it. This doesn’t mean that Step 5 wasn’t useful, but I have to admit that I’ve done no capture with that specific optimization removed to see if it actually causes a meaningful difference. Finally concluding this optimization journey, here’s a table that compares all steps:
| Optimization | Timing | Gain |
|---|---|---|
| Baseline | 4.03ms | 0.00ms |
| FP16 | 2.73ms | 1.30ms |
| Coarse Culling | 2.88ms | -0.15ms |
| Index Buffer | 2.51ms | 0.37ms |
| Z-Curve Index Buffer | 2.37ms | 0.14ms |
| Repack + Quantize | 2.37ms | 0.00ms |
| LOD | 1.06ms | 1.31ms |